
Hosmer-Lemeshow檢驗
05,所以這四項對Y均有顯著性差異,並且觀察平均值和標準差,每項選擇否和是的均值差距也較大,利用視覺化圖形能夠更直觀地觀察到,比如Y和X1,Y和X2如下:構建二元logistic迴歸模型由單個因素進行分析發現X1-X4對於因變數Y都有顯著性
XRDynamic 500|讓止痛藥的藥劑更精確,更安全!
圖 3: 對數座標繪製測試FDC衍射譜圖和由所有結晶組分和背景擬合模擬的譜圖
極簡機器學習課程:使用Python構建和訓練一個完整的人工神經網路
反向傳播反向傳播(back-propagation)是計算深度學習模型引數梯度的方法
DLS奈米粒度儀測試奈米顆粒結果可靠性解析
小結一下,奈米粒徑測試結果可以從下面幾個方面來看:前提:樣品濃度合適,分散劑引數正確A:Z-average和PDI值,是最重要的兩個結果
地基LiDAR點雲資料提取單木樹高和胸徑方法研究
結果表明,提出的格網化擬合圓柱法提取樹高參數和最小二乘擬合圓法提取胸徑引數能得到精度較高的單木引數資訊
關於最佳擬合與最佳擬合補償用這個案例說明
總結:當沒有數模,且需要用向量點構造元素時,為了解決點向量方向不對而帶來的偏差,我們需要選擇最佳擬合重新補償這種演算法
瞭解機器學習基礎
特別是對於計算機視覺和自然語言處理領域中的問題,收集標籤資料可能非常昂貴,因此留出30%的測試資料(比例相當大)可能會使演算法學習起來非常困難,因為用於訓練的資料很少
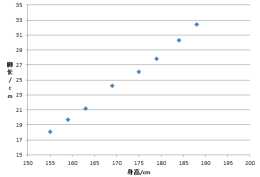
例項分析,如何用最小二乘法做線性迴歸?
樣本特徵值:目標函式:這裡我們假設擬合函式為:這時我們的目標函式就為:然後,透過最小二乘法使目標函式最小,求出這時的θ0和θ1的值,就可以得出擬合曲線了
origin繪圖:誤差的基本表達(三)——置信區間型
第三步:設定擬合數據圖
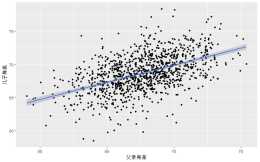
研究生論文中常用的迴歸分析具體方法
官方文件對他的用法解釋是這樣的:官方文件用法解釋官方文件引數比較多,明明同學感覺沒有必要研究那麼多,這裡明明同學講解最常用的方法即:lm(formula, data)formula:表示你要擬合的公式,一般有以下幾種公式中特殊符號表達的含義
Amos路徑分析所得結果模型的修正與調整方法
例如,假如我首先把本文上圖中殘差e1與e4之間的關係加入到路徑圖,重新執行模型,那麼很有可能所得到的新的MI表格中,RoDen對BC具有的影響關係也就消失了

曲面加工最佳化方法
為了提高這類插值軌跡的擬合精度,有文章提出選擇性的插值擬合,先將能夠擬合為樣條的小線段軌跡進行分組,例如每5個點一組,採用三次Bezier曲線對一組刀位點的第一個刀位點P1、第三個刀位點P3和最後一個刀位點P5進行插值,然後判斷P2、P4點
什麼樣的指數最適合定投?
2、中證消費和中證醫藥100是唯二的兩個趨勢線擬合度很高、斜率很大,同時波動率又很高的指數,這就很難得了
用 X 射線衍射法分析固定劑量複方止痛藥的相組成
解決此問題的一種可能解決方案是測量僅包含結晶 APIs 而沒有任何無定形材料的樣品,並將這種圖樣的背景與 FDC 樣品衍射譜圖進行比較
太厲害了!Seaborn也能做多種迴歸分析,統統只需一行程式碼
lmplot(x=“open”, y=“close”, hue=“Up_Down”, data=dataset, logx=True)4、穩健線性迴歸在有異常值

Excel Stat(19):定性資料分析2
此時ExcelStat對最優模型的擬合結果:對應SPSS結果:從擬合上來說兩者並無差異,事實上,兩者的估計值是完全相同的

傳統的正負公差好用嗎?怎麼用?探究一下正負尺寸公差的標註
舉例: 間隙孔軸配合, 板槽配合GX : 最大內切理想模擬體尺寸可用於限制全域性或區域性, 表示目標FOS在給定區間內的最大內切擬合體的尺寸舉例: 間隙孔軸配合, 間隙板槽配合Ⓔ:包容原則通常來說,不帶任何註釋的尺寸公差預設的是(LP),即

冪律分佈擬合神器——Python庫powerlaw
>fit = powerlaw
卡方擬合優度檢驗怎麼做?
卡方擬合優度檢驗的原理在於透過計算實際頻數與預期頻數的差值,且對差值進行平方,最終加和得到卡方值
管理心理學之統計(21)迴歸
由於在迴歸方程中找出a值的公式也保證了被X平均數和Y平均數定義的那個點(MX,MY)在迴歸線上,我們可以透過以下公式確定a和b的值雖然迴歸方程可以被用於預測,但在解釋預測值時,需要注意下面兩點:A