PowerBI多元迴歸預測資料(R語言)
5]),‘置信區間’[name]=“uv”)然後根據度量值,把上下界的GMV預測函式寫出來,順便把合併的區間寫出來,DAX語句如下↓預計GMV上線 =[p97 Intercept] + [p97 UV]*[UV Value] + [p97

如何估算總體比例的置信區間?
252、標準誤差透過類比均值的抽樣分佈標準誤差,得到比例的標準誤差公式為:3、計算結果將所有的值代入置信區間估算公式,可得95%置信區間為:手動帶入公式得出了上面的估算結果,除了自己算,還有更好的選擇——SPSSAU資料科學分析平臺,接下來
origin繪圖:誤差的基本表達(三)——置信區間型
第三步:設定擬合數據圖

GraphPad Prism 9 統計學課堂|置信區間Ⅱ
如果我們假設本研究的受試者代表更大群體,則代表該數值範圍有95%的機率會包括兩種藥物根除率的真正差值

如何用 Excel計算投資組合的在險價值VaR?(雙資產,方差-均方差法)
在險價值VaR的計算公式如下:VaR=投資組合加權平均後的預期收益-(置信區間的Z分數*投資組合收益的標準差)*投資組合的市值通常VaR計算損失機率的時間單位是年,但如果時間單位是星期,需要將計算公式中的預期收益除以一年所擁有的星期數52,
這才是真相,置信區間的理解與運用
由於樣本方差使用一個估計的引數,即平均值,因此,在計算置信區間時使用的t-分佈,其自由度為n-1

什麼是置信區間和置信度
也就是說,這個問題的本質就是用樣本均值去估計總體均值,每次抽樣以後,都可以由樣本的平均值,按照置信度的要求,得到一個置信區間,而這個區間包含總體均值的可能性剛好就是置信度
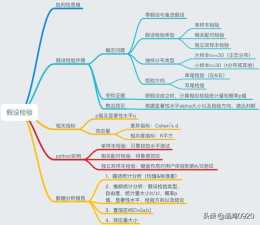
資料分析之假設檢驗
二、假設檢驗的型別與步驟2.1假設檢驗的步驟:確定問題:原假設(H0)與備選假設(H1)假設檢驗型別:根據問題背景,樣本資料特點進行判斷抽樣分佈型別:根據樣本大小確定假設檢驗方向:根據問題背景確定尋找證據:在原假設的基礎上,計算得到檢驗統計
什麼是迴歸分析的置信區間?用Excel函式計算置信區間的3個步驟
許栩原創專欄《從入門到高手:線性迴歸分析詳解》第9章,總體迴歸、置信度、置信區間及其計算方法
請說明置信區間和顯著性水平的區別︱20北大匯豐深財真題解析10
顯著性水平就是變數落在置信區間以外的可能性,“顯著”就是與設想的置信區間不一樣,用α表示

終於有人把p值講明白了
如果p值足夠小,則我們拒絕零假設,並得出實驗有效應(或者說結果統計上顯著)的結論

白話統計閱讀筆記:線性相關係數及其置信區間
線性相關係數通常稱為Pearson相關係數,它給出了兩個變數之間線性相關大小的度量指標,該係數簡單易懂,當r大於0時,說明兩個變數之間存在正相關的關係,而當r小於0時,則說明二者之間為負向的線性相關,當r=0時,說明二者之間沒有線性相關
數學書以外的統計與調查
總體是調查研究物件的全體,樣本是從總體中抽取的部分個體的集合